Kafka for Multi Data Centers (DC) world

Multi-DC World
Today multi DC is real scenario, most companies will run products and services in more than one data center. Distributed workloads in either multiple self managed DC or cloud (SaaS, IaaS or PaaS). A universal data bus (data pipe) is needed for seamless data exchange and integration. Apache Kafka is one of top tool for this job. World leading cloud providers, applications, tools and technologies have ability to connect to Kafka. So it makes sense to use a ubiquitous, scalable and opensource technology than using point solutions. Typical medium and large enterprise application and services deployment
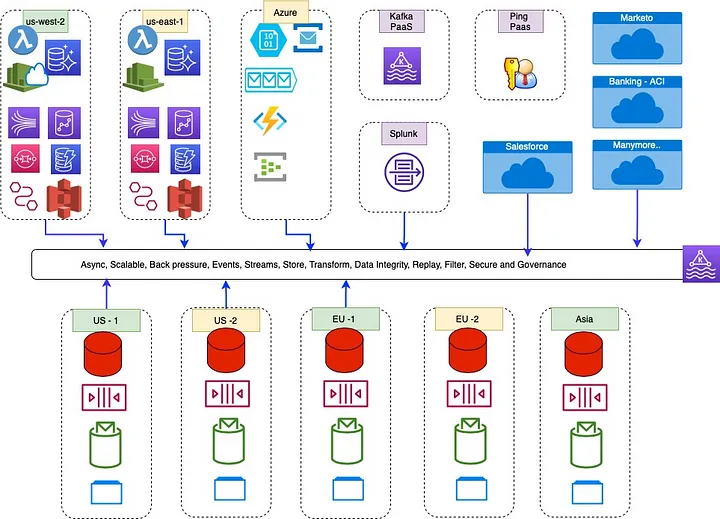
Company has combination of has self managed DC and different cloud providers in different geography. Self managed DC will have databases traditional RDBMS (Oracle, PostgreSQL, MySQL, MS SQL and DB2) also newer database technologies like MongoDB, Elastic, Splunk, Cassandra and more. Messaging like JMS, MQ, RabbitMQ, Tibco and even Kafka topics. Microservices — Java/Node/Go/Python based microservices which produce and consume data. Cloud services like AWS — Eventbridge, Kinesis, Dynamodb, Aurora, Lambda, Cloud Watch and more or Azure — Events, Functions, Databases or PaaS offering like Splunk, Mongo Atlas, Kafka PaaS and many many more. or SaaS vendors like Salesforce, Maketo and tons of others.
Cloud services, popular technologies and databases have Kafka connector. Connect with basic configuration can produce and consume data to Kafka Topic/ecosystem. Kafka also provides connect framework to write your own Java/Scala connectors with predictable lifecycle and Microservices like container/K8s deployment options. Plugin new application and start exchanging data is matter of days not months. Once data is connect to Kafka cluster becomes a reliable, secure, scalable and future proof universal data transfer layer. Lets explore some of top attributes.
- Scalable — Transfer few realtime events of process millions of transaction per second. Store data for weeks or years.
- Reliable — Various QoS quality of services supported like exactly once. Even of consumers are down for extended period automated data catchup
- Secure — Protected APIs, TLS encrypted channels, Encrypt and decrypt specific field, drop or tokenize certain data attribute. Run on encrypted disk.
- Governance — configurable and pluggable data governance. Schema registry of design governance. Industry and solution governance like PCI, PII and others can be implemented.
- Decoupled — Isolated data exchange, changes to one side is not going to impact on other source or target side
- Data Transformation — Data schemas in source and target are never same, Kafka helps to reformat data for consumer. Only data which is required is passed along
Looking at value of using Kafka bases solution should be one of enterprise top choice. In upcoming articles we will explore specific data integration use-cases and how Kafka add enormous value.