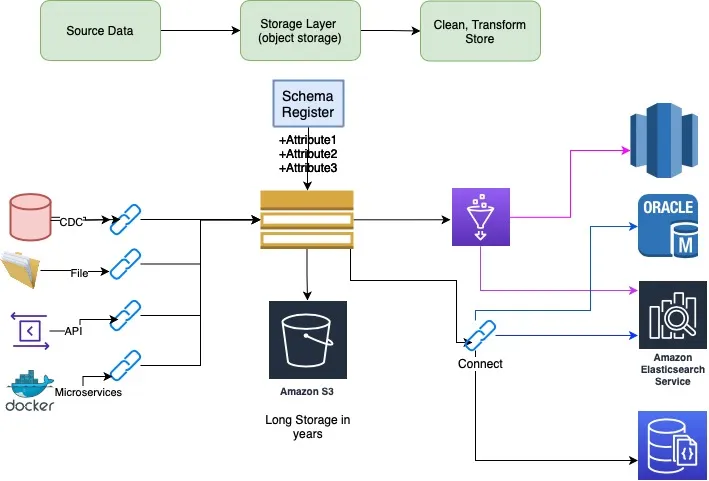
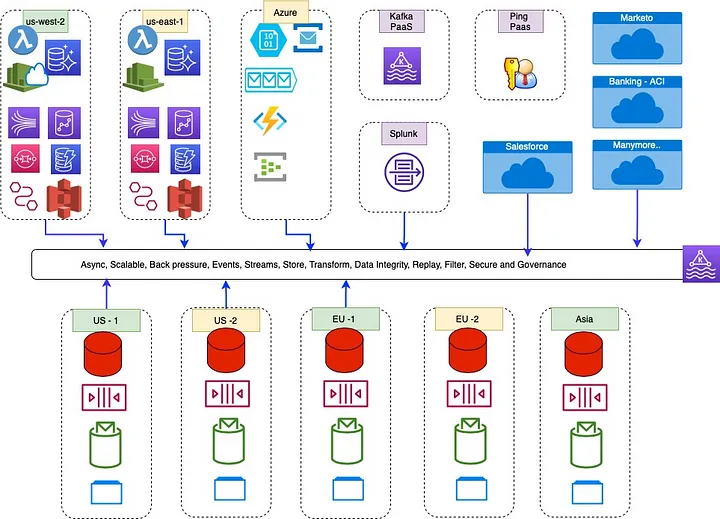
API Quotas & Data Caching in Apache Kafka.

API Processing millions of transactions per min
FDX/OFX is API mechanism to download US Bank account data. EU and UK use openbanking/PSD2 standards. Main challenge with API access is client aggregators tend to overuse the service. Many clients will query more than couple times a day and download multi year data. This results in disproportionate use of services by some users and puts heavy system load.
One solution for equitable use of service to have client quotas. Client or API user will have multiple associated accounts. So rate limit should on account level not on client ID.
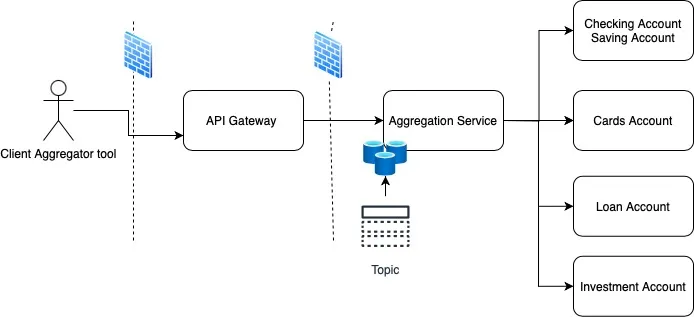
Aggregation Service, collects data from all account services. Typically it will be data for checking, saving, cards, loan and investment account. Quotas are applied to individual account. To limit round trip, quotas should be applied upstream as possible, so good starting point is API Gateway. API gateway rate limits rules are based on identifiable entity, including apps, developers, API keys, access tokens, signed request, certs, IPs and other such things. API gateway will not keep record on how many accounts/day calls were made. Next component is Aggregation service which coordinates, maps and merges data from backend services and send consolidated response.
Exploring Kafka Streams as Caching Layer
Kafka streams have some interesting attributes that we liked. 1) Stream maintains a local partition cache in RocksDB, so round trips to backend is avoided. 2) Works well with microserives we can deploy solution to K8s or VM server, it just a library include. 3) We had working Kafka cluster, so no additional infrastructure needs. Data is isolated between Kafka topic, local cache, share nothing, with no performance impact to other applications. We decided to use Apache Kafka Streams as quota checker and data caching solution.
Solution
- Partition Key — Account was partition key it was unique across bank
- Quote checker — We had a KTable with account id and counter. Business exception response was send back if count exceed.
- Cache TTL — Topic and storage TTL configured for day
- Data Cache — JSON response was mapped and stored in cache
Round Trip,
- API Gateway forwarded the request, service looked up Quote KTable, if this was first request then it make account entry to table.
- Invoked appropriate backend service, mapped the response and save it in Kafka Streams.
- Composed consolidated client response after collecting data from all the services.
- In next call for same account, quota table counter is incremented and consolidated response is picked up and send back to client. Thus saving trips to backend.
This resulted in lot of saving on infrastructure utilization. Improved SLA the total response time came from min to sub second response, aproximate 100x improvement