Data Lake Reimagined

Data lake is a hub location “lake” to source analytics and operational data. Data is typically separated per domain for more modularity and governance controls. Data is sources, clean, transformed and stored in data lake for long period of time.
World is realtime and interconnected a key feature, described here — AWS re:Invent 2022 — Keynote with Dr. Werner Vogels . Trying to refit traditional batch, ETL and data warehouse concepts in new realtime data lake creates more challenges than solutions. Realtime world need a realtime datalake. In this blog we will reimagining some of key building blocks of data lake and create a more robust solution
Typical data lake architecture has following layers

Traditional data lake architecture will have following components
- Source data — Typical consists of one or many data sourcing tools like sftp services (files), Data migration tools, Streaming data tools, API services and CDC tools.
- Storage Layer/Staging Layer — will be typical object store like S3 which can store huge amount of data In this blog we will focus on first 2 layers
rather than using point solution we will use apache kafka for sourcing and storing data . It has lots of advantages over traditional approach
- Kafka connectors and CDC has over 150 connectors types which can start pulling data with simple configuration
- Kafka has rich client APIs with lot of libraries & tools support. Each consumers offset tracks consumed data
- With “kappa” architecture we only need to build one pipeline for batch and realtime data processing
- Kafka has commercial available tiered storage option — Confluent Tiered storage and upcoming opensource KIP — 405 . Data is indirectly stored in S3 like object store with infinite amount of data retention capability
- Schema registry provides data structure for producer, consumers and governance tools. Domain specific canonical schemas will be stored in registry
- Support millions of transaction per sec, highly scalable, fault tolerant and ready for DR
More Kafka Specific Architecture Diagram
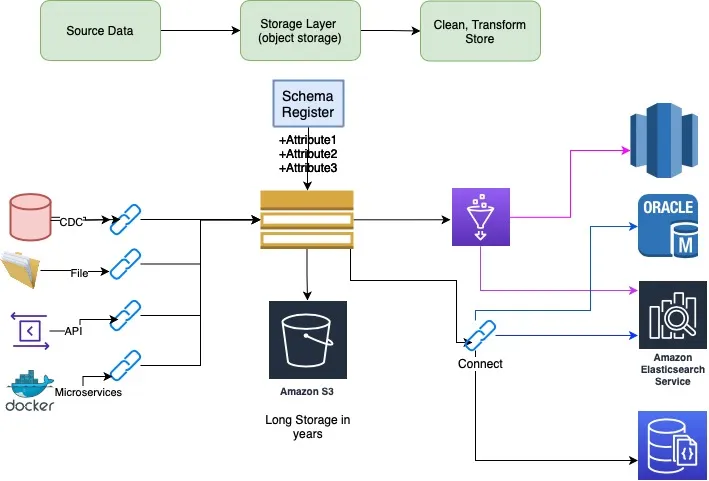
Source connectors are used to source data and put in Kafka topic. Once data is ready in Kafka topic the consumer side can be one of many API consumer from streaming platform like Spark, flink, connector, KSQL, Kafka streams, which will clean, transform and keep domain specific data. The pipeline can evolve over period of time, we can add new consumers as business requirements evolves. New consumers will be able to reply old data from last month or year back all depending on how back data is available on that topic.
Overall this solution simplifies data lake making it more cost effective, efficient and more capable.
References: Kafka based DataLake Kafka Data Lake.